

Google proudly displays the number of web pages contained within its index. At 8 billion pages and counting, this potentially represents an immense quantity of useful information. Indeed, Google is well suited for finding all sorts of arcane trivia tucked into the many recesses of the web.
However, web researchers already recognize that the quantity of data is only one factor. If the information you are searching for is not within one of the 8 billion pages in Google’s index, you’re out of luck.
For example, let’s look at securities filings. Google surprisingly returns Canada’s SEDAR as the first result (gasp!) and the SEC’s EDGAR as the second result. Sacre bleu! Despite French protestations, it turns out that the Internet really is a tool for foisting Canadian (and not American) values and culture onto the world. 🙂
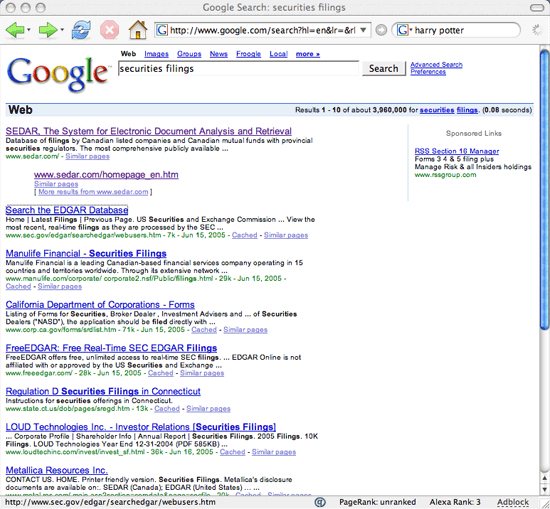
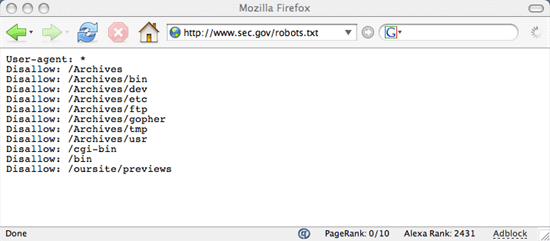
All kidding aside, while Google will point you to the SEC’s web site, this only represents a first albeit incomplete step since the contents of the securities filings are not included in the Google index. This is true even though these securities filings are freely accessible online and are not sequestered in a password-protected section of the web site. So, you cannot search for every mention of a particular executive within a company’s securities filings through Google. However, the fault for this omission lies with the SEC and not with Google, Yahoo or MSN. For some reason, the SEC has set-up a robots.txt file to hide securities filings and other files from search engines. Unfortunately, this effectively banishes securities filings to the Deep Web. So, on one hand, the SEC promotes the disclosure of important corporate data to investors; however, on the other hand, the SEC itself hides the disclosures it receives from the search engines – the usual way people go about finding information.
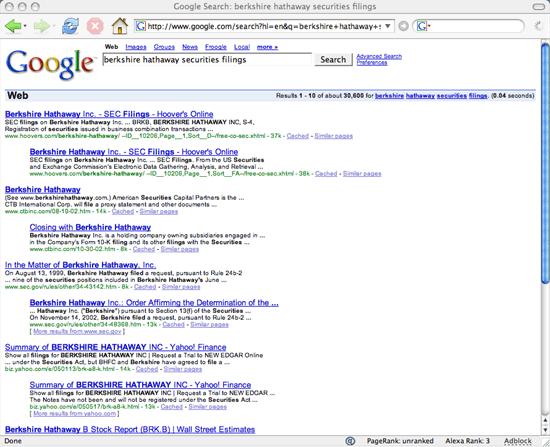
That’s why when I searched for berkshire hathaway securities filings, Google returned the copies from Hoover’s Online, and the SEC’s own copies are no where to be found. Unfortunately, Hoover’s also blocks search engines from indexing the contents of its securities filings as well. So, Google can tell you that Hoover’s Online has a copy of Berkshire Hathaway’s securities filings, but cannot tell you what is inside them.
As a result, researchers have to go through the circuitous route of looking through each individual securities filing to track down the information they need or pay one of the subscription services which offers the ability to conduct full-text searches of securities filings. For those only interested in material contracts, Onecle has extracted thousands of business contracts from securities filings and these are all freely accessible, as well as searchable from Google.
In other search engine news, this week, Yahoo! announced Yahoo! Search Subscriptions – a new service for searching through subscription content. While Yahoo! Search Subscriptions is currently only configured to search through Consumer Reports, Forrester Research, FT.com, IEEE, the New England Journal of Medicine, TheStreet.com and the Wall Street Journal right now, Yahoo! states that its search engine will add Lexis-Nexis and other subscription content at a later time. Let’s see how well this new service works so far by using three different approaches to locate Kozlowski in the Wall Street Journal.
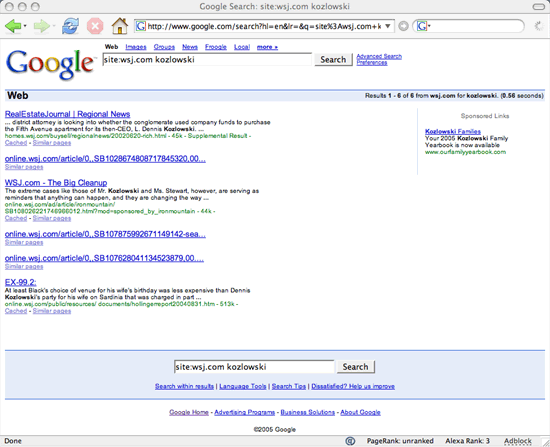
Using Google, a search for Kozlowski on the Wall Street Journal site returns 6 results.
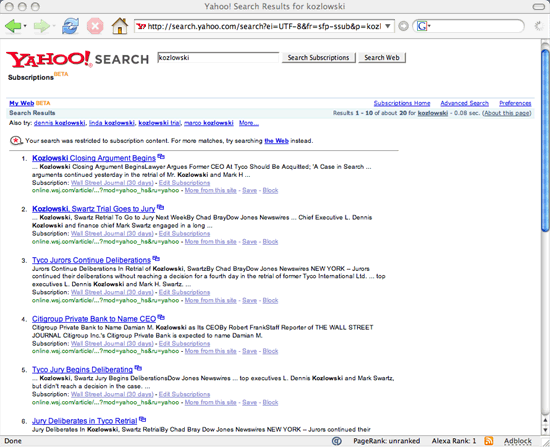
If I run the same search using Yahoo! Search Subscriptions, I get 20 matching results. Interestingly, if I ran a search for Kozlowski using the regular Yahoo! Search instead of Yahoo! Search Subscriptions, I only get back 2 matching results from the Wall Street Journal.
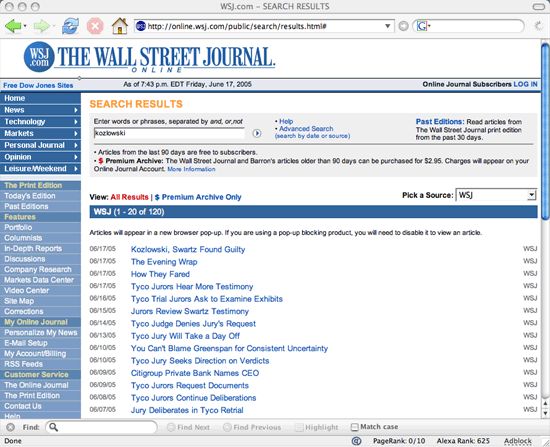
The final test is running a search for Kozlowski on the Wall Street Journal site itself. And the winner is…the Wall Street Journal with 120 matching results. This shows you how much content still remains out-of-reach of the major search engines. Google may have over 8 billion web pages stored in its index, but it isn’t omniscient (yet). Not by a long shot!




